이진 탐색 트리
개요
얼마 전 백준에서 집합 자료형을 구현하는 문제를 보았습니다. 직접 구현하라고 하면 가물가물하면서 `std::set` 같은 컨테이너를 쓰는 것이 양심에 찔려서, 자료구조 공부도 다시 시작했습니다. 오늘은 가장 먼저 이진 탐색 트리(Binary Search Tree)를 살펴봅니다.
이진 탐색 트리란
정의와 성질
이진 탐색 트리는 이진 트리면서, 다음과 같은 재귀적인 성질을 가진 트리입니다.
이진 탐색 트리의 성질
노드를 기준으로 왼쪽 트리에 있는 노드들은 더 작은 키(key)를 가진다. 오른쪽 트리에 있는 노드들은 더 큰 키를 가진다.
성질에서 알 수 있듯, 이진 탐색 트리는 키-값(key-value)의 데이터를 저장하는 자료구조입니다. 이 글에서는 편의상 키와 값은 모두 정수이며, 두 값이 같다고 가정하겠습니다. 아래 그림의 두 트리는 모두 위의 성질을 만족하는 이진 탐색 트리입니다.

이진 탐색 트리는 성질 상 탐색, 삽입, 삭제 등 연산의 시간 복잡도가 트리의 높이에 비례합니다. 따라서 같은 데이터를 저장하는 트리라도 형태에 따라 복잡도의 차이가 생길 수 있습니다. 그림에서 왼쪽의 경우 $O(\log n)$의 시간 복잡도를 갖지만, 오른쪽과 같이 비효율적인 경우 최악에는 $O(n)$의 복잡도를 갖게 됩니다.
구조체와 함수 선언
자료구조 구현은 모두 C언어로 하겠습니다. 트리의 노드에 해당하는 `Node` 구조체는 키와 값을 나타내는 `key` 와 `value` , 각각 왼쪽 자식, 오른쪽 자식, 부모 노드를 가리키는 포인터 `left` , `right` , `parent` 를 멤버로 가집니다. 이진 탐색 트리를 나타내는 `BST` 구조체는 루트 노드를 가리키는 포인터 `root` 를 멤버로 가집니다.
typedef struct Node {
int key, value;
struct Node *left, *right, *parent;
} Node;
typedef struct BinarySearchTree {
Node *root;
} BST;
이진 탐색 트리의 연산을 구현하기 위한 함수들은 다음과 같습니다.
// 모든 노드를 키 순으로 출력합니다.
void print(BST *bst);
// 주어진 키를 가진 노드를 찾아 반환합니다.
Node *search(BST *bst, int key);
// 키 순으로 정렬했을 때 하나 작은 키를 가진 노드를 반환합니다.
Node *prev(BST *bst, int key);
// 키 순으로 정렬했을 때 하나 큰 키를 가진 노드를 반환합니다.
Node *next(BST *bst, int key);
// 새로운 노드를 삽입합니다.
void insert(BST* bst, int key, int value);
// 주어진 키를 가진 노드를 삭제합니다.
void delete(BST *bst, int key);
위의 함수들을 구현하기 위해 내부적으로 다음과 같은 내장 함수들을 사용합니다. 함수 이름 앞에 언더스코어(underscore) 두 개가 붙어 있으면 내장 함수로 구분하겠습니다. 이 함수들의 필요성과 쓰임에 대해서는 밑에서 하나씩 살펴볼 예정입니다.
// 노드를 기준으로 중위 순회하며 키와 값을 출력합니다.
void __tree_walk(Node *x);
// 노드를 기준으로 하위 트리에서 주어진 키를 가진 노드를 찾아 반환합니다.
Node *__tree_search(Node *x, int key);
// 노드를 기준으로 왼쪽 트리에서 가장 작은 키를 가진 노드를 반환합니다.
Node *__tree_min(Node *x);
// 노드를 기준으로 오른쪽 트리에서 가장 큰 키를 가진 노드를 반환합니다.
Node *__tree_max(Node *x);
// 키 순으로 정렬했을 때 노드의 키보다 하나 작은 키를 가진 노드를 반환합니다.
Node *__tree_predecessor(Node *x);
// 키 순으로 정렬했을 때 노드의 키보다 하나 큰 키를 가진 노드를 반환합니다.
Node *__tree_successor(Node *x);
// 트리에서 노드 u의 위치에 노드 v를 대입합니다.
void __transplant(BST *bst, Node *u, Node *v);
트리 순회하기
이제 제일 쉬운 함수부터 하나씩 구현해 봅시다. 가장 먼저 순회는 아주 쉬운데, 이진 트리를 중위 순회(in-order)해주면 됩니다. 이진 탐색 트리의 성질로 인해 키가 작은 노드부터 정렬된 순서로 순회하게 됩니다.

순회를 위한 내장 함수 `__tree_walk` 는 재귀 호출을 이용해 구현합니다. 왼쪽 트리를 재귀적으로 순회하고, 자신의 키와 값을 출력하고, 다시 오른쪽 트리를 재귀적으로 순회하는 방식입니다. 트리의 출력을 위한 `print` 함수는 루트 노드를 기준으로 순회를 수행하면 됩니다.
// 내장 함수
void __tree_walk(Node *x) {
if (x != NULL) {
__tree_walk(x->left);
printf("%d %d\n", x->key, x->value);
__tree_walk(x->right);
}
}
void print(BST *bst) {
__tree_walk(bst->root);
}
키를 가진 노드 찾기
다음은 탐색입니다. 탐색은 특정 키를 가진 노드를 찾는 연산으로, 사용하는 언어가 딕셔너리(dictionary), 맵(map), 연관 배열(associative array) 같은 이름의 자료구조를 지원한다면 숱하게 쓰는 연산입니다. 이진 탐색 트리는 이진 탐색을 통해 평균적으로 $O(\log n)$ 시간에 특정 키를 가진 노드를 찾을 수 있습니다. 아래 그림은 이진 탐색을 통해 키 `13` 을 가진 노드를 찾는 과정을 나타내고 있습니다.

탐색을 위한 내장 함수 `__tree_search` 는 노드 `x` 의 키와 주어진 `key` 를 반복하여 비교합니다. 주어진 `key` 가 더 크다면 `x` 의 오른쪽 자식을 `x` 에 대입하여 오른쪽 트리에서 반복을 계속합니다. `key` 가 더 작은 경우 왼쪽 트리에서 반복을 계속합니다. 반복문의 종료 조건으로 `x` 의 키와 `key` 가 일치하면 성공적으로 찾은 경우입니다. `x` 가 `NULL` 이 되는 경우는 주어진 `key` 를 찾지 못한 경우입니다.
탐색 연산은 일반적인 이진 탐색과 매우 유사합니다. `__tree_walk` 와 같이 재귀적으로 구현할 수도 있으나, 반복적으로 구현하는 쪽이 함수 호출과 반환에 필요한 시간과 공간을 아낄 수 있습니다. 트리에서의 탐색 연산을 위한 `__search` 함수는 루트 노드를 기준으로 탐색을 수행하면 됩니다.
// 내장 함수
Node *__tree_search(Node *x, int key) {
while (x != NULL && x->key != key) {
x = (key < x->key) ? x->left : x->right;
}
return x;
}
Node *search(BST *bst, int key) {
return __tree_search(bst->root, key);
}
같은 원리로 가장 작은 키를 가진 노드를 반환하는 `__tree_min` , 가장 큰 키를 가진 노드를 반환하는 `__tree_max` 내장 함수도 구현할 수 있습니다. 이진 탐색 트리의 성질에 따라 왼쪽 자식만 따라가면 가장 작은 키, 오른쪽 자식만 따라가면 가장 큰 키가 나오게 됩니다.
Node *__tree_search(Node *x, int key) {
while (x != NULL && x->key != key) {
x = (key < x->key) ? x->left : x->right;
}
return x;
}
Node *__tree_min(Node *x) {
while (x->left != NULL) {
x = x->left;
}
return x;
}
이전과 다음 노드 찾기
이진 탐색 트리는 정렬된 자료구조입니다. 정렬된 자료구조에서는 특정 데이터의 이전 순서나 다음 순서의 데이터를 조회해야 하는 경우가 있습니다. 그런데 이진 탐색 트리의 성질을 활용하면, 이전 순서나 다음 순서를 찾기 위해 키를 서로 비교하지 않고도 이들 노드를 찾아낼 수 있습니다.
먼저 다음 순서를 찾는 연산을 보겠습니다. 다음 순서를 찾을 때는 트리의 형태에 따라 그림과 같이 두 가지 경우가 존재합니다. 그림의 왼쪽은 `3` 의 다음 노드 `4` 를 찾는 과정으로, `3` 의 오른쪽 자식이 존재하고 있습니다. 이진 탐색 트리의 성질에 따라, 오른쪽 자식이 존재하는 경우 오른쪽 트리에서 키가 최솟값인 노드를 찾으면 됩니다. 현재 노드보다 키가 큰 노드들 중에서 가장 작은 노드를 찾으면 그것이 다음 노드이기 때문입니다.

그림의 오른쪽은 `5` 의 다음 노드가 `6` 을 찾고 있습니다. 그런데 `5` 는 오른쪽 자식 노드가 없습니다. 이런 경우에도 자기보다 키가 작은 노드는 왼쪽 트리, 큰 노드는 오른쪽 트리에 존재한다는 성질을 이용합니다. 기준 노드의 조상 노드들을 조회하면서 기준 노드를 왼쪽 트리의 노드로 갖는 첫 번째 조상을 찾으면, 키의 비교 없이도 다음 노드를 찾을 수 있습니다. 더욱 복잡한 이 경우도 최악의 시간 복잡도가 트리의 높이에 비례하므로, 다음 노드를 찾는 연산의 시간 복잡도는 $O(\log n)$ 입니다.
노드를 기준으로 다음 노드를 찾는 내장 함수 `__tree_successor` 는 두 경우를 구분하기 위한 분기문이 존재합니다. 4행은 오른쪽 자식이 존재하는 경우로, `__tree_min` 함수를 이용해 오른쪽 트리에서 키가 최솟값인 노드를 찾아 반환합니다. 7행은 오른쪽 자식이 없는 경우로, 이 때는 두 노드의 관계를 비교하기 위해 기준 노드 `x` 의 부모를 가리키는 포인터 `y` 를 사용합니다. `x` 는 부모 노드를 가리키는 포인터를 계속 따라가면서, `y` 가 `x` 의 부모를 가리키도록 계속 갱신합니다. 처음으로 `x` 가 `y` 의 왼쪽 자식이 되는 순간, `y` 를 반환합니다.
주어진 키에 대한 다음 노드를 반환하는 연산에 해당하는 `next` 함수는 앞서 구현한 내장 함수 `__tree_search` 를 이용해 주어진 키를 가진 노드를 찾습니다. 이후 해당 노드에 대해 내장 함수 `__tree_successor` 를 호출하여 다음 노드를 찾아 반환합니다.
// 내장 함수
Node *__tree_successor(Node *x) {
Node *y = x->parent;
if (x->right != NULL) {
return __tree_min(x->right);
}
while (y != NULL && x == y->right) {
x = y;
y = y->parent;
}
return y;
}
Node *next(BST *bst, int key) {
Node *x = __tree_search(bst->root, key);
return __tree_successor(x);
}
이전 순서를 찾을 때도 트리의 형태에 따라 두 가지 경우가 존재합니다. 다음 순서를 찾을 때와 똑같이 처리하면 됩니다. 왼쪽 자식이 있는 경우는 왼쪽 트리에서 최댓값을 반환합니다. 왼쪽 자식이 없는 경우, 조상 노드들을 조회하면서 기준 노드를 오른쪽 트리의 노드로 갖는 첫 번째 조상을 찾아야 합니다.
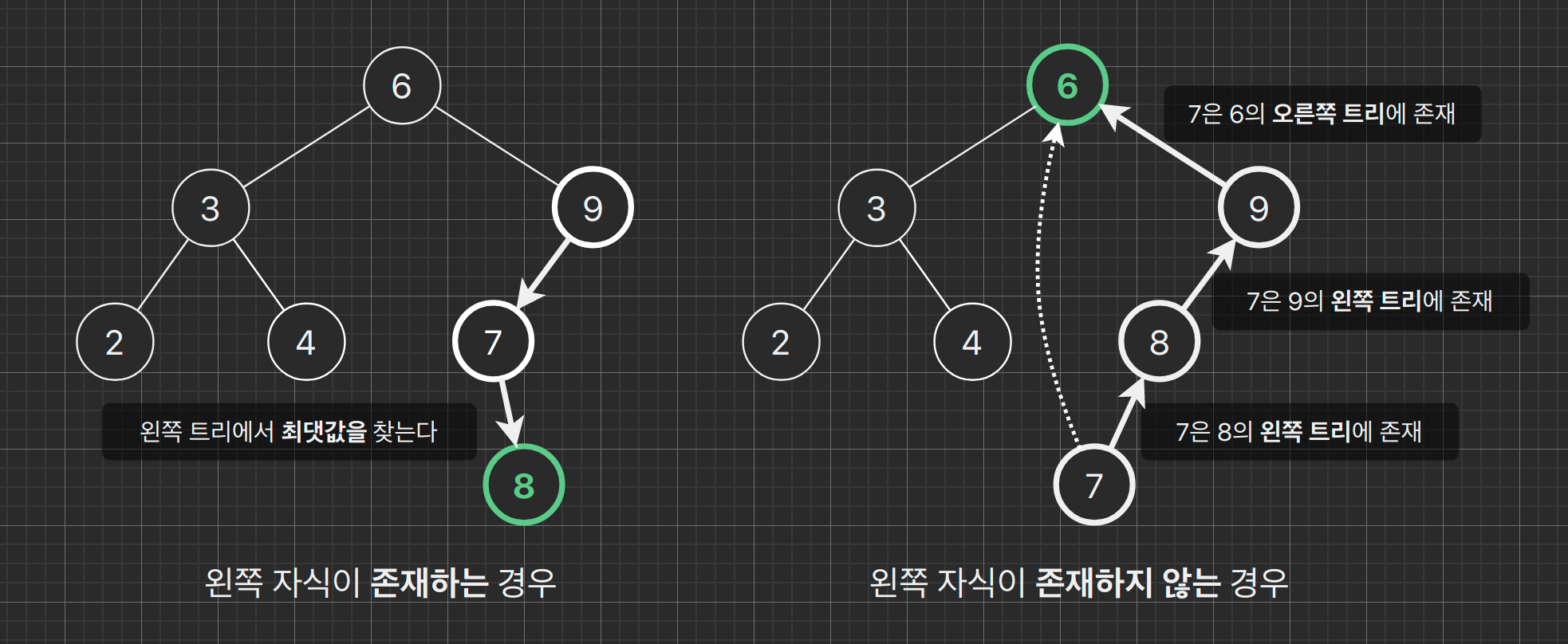
이전 노드를 찾는 내장 함수 `__tree_predecessor` 와, 주어진 키에 대한 이전 노드를 찾는 함수 `prev` 는 다음 노드를 찾는 코드와 똑같은 원리로 구현하면 됩니다. 단, 사용하는 함수가 `__tree_min` 에서 `__tree_max` 로 바뀌는 등 방향만 바꿔줍니다.
// 내장 함수
Node *__tree_predecessor(Node *x) {
Node *y = x->parent;
if (x->left != NULL) {
return __tree_max(x->right);
}
while (y != NULL && x == y->left) {
x = y;
y = y->parent;
}
return y;
}
Node *prev(BST *bst, int key) {
Node *x = __tree_search(bst->root, key);
return __tree_predecessor(x);
}
트리에 노드 삽입하기
새로운 노드를 이진 탐색 트리에 추가하는 연산은 삽입 연산입니다. 삽입 연산은 새로운 노드를 항상 리프 노드로 추가하면 쉽게 구현할 수 있습니다. 아래 그림은 이진 탐색 트리에 새로운 키 `7` 을 가진 노드를 삽입하는 과정을 나타내고 있습니다.

노드를 삽입하기 위해서는, 이진 탐색을 통해 삽입할 노드를 자식으로 가질 노드를 찾아야 합니다. 삽입할 노드를 왼쪽 자식으로 가질 노드라면 기존에 왼쪽 자식이 없어야 하고, 오른쪽 자식으로 가질 노드라면 오른쪽 자식이 없어야 합니다. 그림에서는 이진 탐색을 통해 키 `7` 의 새로운 노드를 삽입할 노드를 찾습니다. 키 `8` 을 가진 노드가 왼쪽 자식이 없으면서, `7` 은 `8` 보다 작으니 해당 노드의 왼쪽 자식으로 삽입하는 것입니다. 삽입 연산의 시간 복잡도 또한 트리의 높이에 비례하므로, $O(\log n)$ 입니다.
삽입 연산을 구현한 `insert` 함수는 키와 값을 인자로 받고, `malloc` 함수를 통해 새로운 노드를 생성합니다. 이후 6행에서 루트 노드에서 시작하는 포인터 `x` 와, `x` 의 부모를 가리키는 포인터 `y` 를 이용하여 이진 탐색을 수행합니다. 반복문의 종료 조건은 `y` 의 자식 `x` 가 `NULL` 이 되는 것으로, 이때의 `x` 의 위치가 새로운 노드를 삽입해야 할 위치입니다. 12행에서는 주어진 키 값과 `y` 의 키 값을 비교하여, 왼쪽 자식으로 삽입할지 오른쪽 자식으로 삽입할지 결정합니다. 만약 이진 탐색 트리가 비어 있었다면 새로운 노드를 루트 노드로 설정합니다.
void insert(BST* bst, int key, int value) {
Node *newnode = malloc(sizeof(Node));
Node *x = bst->root, *y = NULL;
*newnode = (Node) { key, value, NULL, NULL, NULL };
while (x != NULL) {
y = x;
x = (newnode->key < x->key) ? x->left : x->right;
}
newnode->parent = y;
if (y == NULL) { // 이진 탐색 트리가 비어 있는 경우
bst->root = newnode;
} else if (newnode->key < y->key) {
y->left = newnode;
} else {
y->right = newnode;
}
}
트리에서 노드 삭제하기
트리에서 노드를 삭제하는 연산은 구현 중 다소 까다로운 부분입니다. 항상 새로운 노드를 리프 노드로 추가하는 삽입 연산과 달리, 노드를 중간에서 삭제하게 되면 트리의 형태가 변형되기 때문입니다. 노드를 삭제할 때는 삭제할 노드가 가진 자식의 개수에 따라 경우가 나누어집니다. 아래 그림은 트리에서 키 `3` 을 가진 노드를 삭제하는 모습으로, 삭제할 노드가 자식이 아예 없거나 하나인 경우입니다.

그림의 경우는 비교적 단순한 경우로, 자식이 없는 경우는 단순히 삭제하면 됩니다. 자식이 하나 있는 경우는 해당 자식 노드를 삭제할 노드 위치에 대입하면, 이진 탐색 트리의 성질을 유지하면서 삭제를 수행할 수 있습니다. 사실 이 둘은 구현 상으로는 동일한 경우입니다. 자식이 없는 경우도 `NULL` 자식 노드가 있어 삭제할 위치에 `NULL` 을 대입한다고 생각하면 자식이 하나인 경우와 같은 코드로 처리할 수 있기 때문입니다.
반면 자식이 두 개 있는 경우는 조금 복잡합니다. 이 때는 트리에서 순서 상 다음 노드를 찾은 후, 다음 노드가 삭제할 노드의 오른쪽 자식인지 아닌지에 따라 경우가 나뉘게 됩니다. 먼저 다음 노드가 오른쪽 자식인 경우는 다음 노드를 삭제할 노드 위치에 대입합니다. 이 때 이진 탐색 트리의 성질에 의해 다음 노드는 왼쪽 자식이 없습니다. 만약 왼쪽 자식이 있으면 그쪽이 다음 노드가 되어 모순이기 때문입니다. 따라서 삭제할 노드 위치에 대입하여도, 삭제할 노드의 왼쪽 자식을 그대로 왼쪽 자식으로 가질 수 있습니다.

다음 노드가 삭제할 노드의 오른쪽 자식이 아닐 수도 있습니다. 이 때 삭제할 노드를 $x$, 삭제할 노드의 오른쪽 자식을 $r$, 삭제할 노드의 다음 노드를 $y$ 라고 하겠습니다. 이 경우에는 트리를 두 번 움직여 주어야 합니다. 먼저 다음 노드 $\pmb{y}$의 오른쪽 자식을 $\pmb{y}$ 위치에 대입합니다. 이후 $\pmb{y}$를 삭제할 노드 $\pmb{x}$ 위치에 대입한 후, $x$의 오른쪽 자식 $r$과 연결해줍니다. 앞서 말했듯 다음 노드 $y$ 는 왼쪽 자식이 없어, 두 작업 모두 전혀 문제가 되지 않습니다.

삭제 연산은 모든 경우에서 노드를 다른 노드의 위치에 대입하는 작업이 필요합니다. 따라서 먼저 대입을 위한 내장 함수 `__transplant` 를 구현하겠습니다. 이 함수는 노드 `v` 를 노드 `u` 위치에 대입한 후, 기존 노드 `u` 의 부모가 새로운 노드 `v` 를 자식으로 갖도록 합니다. 다만 새로운 노드 `v` 의 자식 포인터들을 연결하는 작업은 하지 않아, 함수를 호출한 쪽에서 직접 해야 합니다.
void __transplant(BST *bst, Node *u, Node *v) {
if (u->parent == NULL) { // u가 루트 노드인 경우
bst->root = v;
} else if (u == u->parent->left) { // u가 왼쪽 자식이었다면
u->parent->left = v;
} else { // u가 오른쪽 자식이었다면
u->parent->right = v;
}
if (v != NULL) {
v->parent = u->parent;
}
}
이제 `__transplant` 함수를 이용해서 삭제 함수를 편하게 구현할 수 있습니다. 삭제 연산을 위한 `delete` 함수는 키 `key` 를 받아, 내장 함수 `__tree_search` 를 호출하여 삭제할 노드 `x` 를 찾고 삭제합니다. 4행과 6행은 삭제할 노드 `x` 의 자식이 없거나 하나인 경우로, `__transplant` 함수를 호출해 자식 또는 `NULL` 을 `x` 위치에 대입합니다.
9행은 `x` 의 자식이 둘인 경우입니다. 이 경우는 먼저 `x` 의 오른쪽 트리에서 다음 노드 `y` 를 찾습니다. 11행은 `y` 가 `x` 의 오른쪽 자식이 아닌 경우로, 위의 그림과 같이 `y` 의 오른쪽 자식을 `y` 위치에 대입시켜 놓습니다. 이후 `y` 가 `x` 의 오른쪽 자식 (그림에서 $r$)의 부모가 되도록 연결합니다. 그러면 16행에서, 다음 노드가 `x` 의 오른쪽 자식인 경우와 똑같이 `y` 를 `x` 위치에 대입만 해주면 됩니다. 대입 후 `y` 의 자식에 대한 포인터 연결은 직접 해야 함에 유의합니다.
void delete(BST *bst, int key) {
Node *x = __tree_search(bst->root, key), *y;
if (x->left == NULL) {
__transplant(bst, x, x->right);
} else if (x->right == NULL) {
__transplant(bst, x, x->left);
} else {
y = __tree_min(x->right);
if (y->parent != x) {
__transplant(bst, y, y->right);
y->right = x->right;
y->right->parent = y;
}
__transplant(bst, x, y);
y->left = x->left;
y->left->parent = y;
}
}
이진 탐색 트리 사용해보기
이진 탐색 트리의 모든 연산을 구현했으니, 직접 사용해 봅시다. 아래는 `BST` 구조체를 사용하는 테스트 코드입니다. 5행은 이진 탐색 트리에 1부터 10까지의 키를 뒤죽박죽 삽입하고 출력합니다. 삽입은 그렇게 해도 출력은 작은 순서대로 잘 나와줍니다. 10행은 키 1~3을 삭제하고, 11~13을 새로 집어넣은 후 또 출력합니다. 이번에도 4부터 13까지 작은 순서대로 잘 출력됩니다.
int main() {
int arr[10] = { 5, 3, 9, 2, 6, 7, 4, 1, 10, 8 };
BST bst = { NULL };
for (int i = 0; i < 10; i++) {
insert(&bst, arr[i], arr[i]);
}
print(&bst);
delete(&bst, 3);
delete(&bst, 2);
delete(&bst, 1);
insert(&bst, 11, 11);
insert(&bst, 12, 12);
insert(&bst, 13, 13);
print(&bst);
return 0;
}
결론
이진 탐색 트리는 키-값 데이터를 정렬된 순서로 관리할 수 있고, 삽입과 삭제 등의 모든 연산을 이상적으로는 $\pmb{O(\log n)}$ 시간에 처리할 수 있습니다. 하지만 트리의 형태에 따라 최악의 경우 $\pmb{O(n)}$ 시간까지 걸릴 수 있습니다. 이 경우에는 선형 자료구조에 비해 별로 좋은 점이 없습니다.
따라서 인해 집합이나 딕셔너리 등 컨테이너의 구현에는 트리의 형태를 효율적인 형태로 유지하도록 하는 알고리즘이 추가된 자가 균형(self-balancing) 이진 탐색 트리를 사용합니다. 실제로 리눅스의 `g++` 컴파일러가 사용하는 C++ 라이브러리를 동적 분석한 결과, `std::set` 의 구현에 자가 균형 이진 탐색 트리의 일종인 레드-블랙 트리(Red-Black Tree)를 사용하고 있었다고 합니다.
참고자료
[1] T.H. Corman, C.E. Leiserson, R.L. Rivest and C. Stein, "Binary Search Trees," in Introduction to Algorithms, 3rd ed. Cambridge, MA: MIT Press, 2009, pp. 286-298.
부록
이진 탐색 트리 구현 코드
#include <stdio.h>
#include <stdlib.h>
/* Definitions */
typedef struct Node {
int key, value;
struct Node *left, *right, *parent;
} Node;
typedef struct BinarySearchTree {
Node *root;
} BST;
/* Internal Functions */
void __tree_walk(Node *x) {
if (x != NULL) {
__tree_walk(x->left);
printf("%d %d\n", x->key, x->value);
__tree_walk(x->right);
}
}
Node *__tree_search(Node *x, int key) {
while (x != NULL && x->key != key) {
x = (key < x->key) ? x->left : x->right;
}
return x;
}
Node *__tree_min(Node *x) {
while (x->left != NULL) {
x = x->left;
}
return x;
}
Node *__tree_max(Node *x) {
while (x->right != NULL) {
x = x->right;
}
return x;
}
Node *__tree_predecessor(Node *x) {
Node *y = x->parent;
if (x->left != NULL) {
return __tree_max(x->right);
}
while (y != NULL && x == y->left) {
x = y;
y = y->parent;
}
return y;
}
Node *__tree_successor(Node *x) {
Node *y = x->parent;
if (x->right != NULL) {
return __tree_min(x->right);
}
while (y != NULL && x == y->right) {
x = y;
y = y->parent;
}
return y;
}
void __transplant(BST *bst, Node *u, Node *v) {
if (u->parent == NULL) {
bst->root = v;
} else if (u == u->parent->left) {
u->parent->left = v;
} else {
u->parent->right = v;
}
if (v != NULL) {
v->parent = u->parent;
}
}
/* Exposed Functions */
void print(BST *bst) {
__tree_walk(bst->root);
}
Node *prev(BST *bst, int key) {
Node *x = __tree_search(bst->root, key);
return __tree_predecessor(x);
}
Node *next(BST *bst, int key) {
Node *x = __tree_search(bst->root, key);
return __tree_successor(x);
}
void insert(BST* bst, int key, int value) {
Node *newnode = malloc(sizeof(Node));
Node *x = bst->root, *y = NULL;
*newnode = (Node) { key, value, NULL, NULL, NULL };
while (x != NULL) {
y = x;
x = (newnode->key < x->key) ? x->left : x->right;
}
newnode->parent = y;
if (y == NULL) { // bst is empty
bst->root = newnode;
} else if (newnode->key < y->key) {
y->left = newnode;
} else {
y->right = newnode;
}
}
void delete(BST *bst, int key) {
Node *x = __tree_search(bst->root, key), *y;
if (x->left == NULL) {
__transplant(bst, x, x->right);
} else if (x->right == NULL) {
__transplant(bst, x, x->left);
} else {
y = __tree_min(x->right);
if (y->parent != x) {
__transplant(bst, y, y->right);
y->right = x->right;
y->right->parent = y;
}
__transplant(bst, x, y);
y->left = x->left;
y->left->parent = y;
}
}
/* Driver Code */
int main() {
int arr[10] = { 5, 3, 9, 2, 6, 7, 4, 1, 10, 8 };
BST bst = { NULL };
for (int i = 0; i < 10; i++) {
insert(&bst, arr[i], arr[i]);
}
print(&bst);
delete(&bst, 3);
delete(&bst, 2);
delete(&bst, 1);
insert(&bst, 11, 11);
insert(&bst, 12, 12);
insert(&bst, 13, 13);
print(&bst);
return 0;
}